
Thuật toán là thuật ngữ được sử dụng rộng rãi trong lĩnh vực lập trình và khoa học máy tính. Vậy thuật toán là gì? Có bao nhiêu thuật toán cơ bản được sử dụng trong lập trình? Độ phức tạp của thuật toán ra sao? Nếu bạn đang tìm hiểu các vấn đề này thì bài viết dưới đây của Vieclam24h.vn chắc chắn dành cho bạn. Cùng theo dõi nhé!
Thuật toán là gì?

Thuật toán hay thuật giải, giải thuật (Algorithm) là tập hợp các câu lệnh, các phương pháp, chỉ thị hoặc các bước thực hiện theo thứ tự nhất định nhằm giải quyết một vấn đề logic bằng chương trình máy tính. Kỹ năng về thuật toán là nền tảng trong lĩnh vực lập trình, do đó, các lập trình viên phải nắm vững kỹ năng này mới có thể làm việc hiệu quả.
Đặc điểm của thuật toán là gì?
1. Tính chính xác (Precision): Thuật toán là tập hợp các bước rõ ràng, trình tự nhất định và có thể thực thi để ra được kết quả tối ưu nhất. Do đó, đây là yếu tố quan trọng nhất, mang tính khả dụng và khách quan của thuật toán.
2. Tính hữu hạn (Finiteness): Thuật toán phải giới hạn số lệnh, tức là các lệnh trong thuật toán phải đếm được. Mọi thuật toán được sử dụng nhằm thực hiện một công việc nhất định, nếu thuật toán không đáp ứng tính hữu hạn thì thuật toán đó sẽ bị lặp vô tận, không cho ra kết quả cuối cùng.
Đầu vào (Input): Thuật toán thường yêu cầu một số giá trị đầu vào.
Đầu ra (Output): Khi kết thúc thuật toán, bạn sẽ nhận được một hoặc nhiều kết quả.
3. Tính rõ ràng (Unambiguity): Thuật toán luôn được sắp xếp theo trình tự nhất định, các nguyên tắc lệnh hợp lý để các thao tác được diễn ra trơn tru và nhanh gọn nhất có thể.
4. Tính khả dụng (Possibility): Thuật toán không chỉ sử dụng cố định trong một bài toán mà có thể ứng dụng linh hoạt trong nhiều bài toán tương tự nhau.
5. Tính khách quan (Objectivity): Dù giải theo cách nào thì một thuật toán cũng chỉ cho ra một đáp án duy nhất. Điều này khẳng định sự tuyệt đối trong kết quả bài toán. Nếu kết quả cho ra khác nhau thì bạn cần xem xét lại quá trình xử lý.
Lý do nên sử dụng thuật toán là gì?
Trong lập trình, có nhiều hướng tiếp cận để giải quyết một vấn đề. Tuy nhiên, không phải các phương pháp đều cho ra hiệu suất giải quyết vấn đề và hiệu quả như nhau. Do đó, việc chọn lựa và sử dụng đúng thuật toán là chìa khóa quan trọng để tối ưu hóa hiệu suất làm việc.
Bên cạnh đó, độ chính xác của phần mềm đóng vai trò quan trọng trong việc xác định hiệu suất làm việc. Thuật toán chính là bí quyết để đảm bảo độ chính xác trong quá trình xử lý thông tin. Khi sử dụng một thuật toán tốt, chương trình máy tính có thể tạo ra kết quả với độ chính xác cao. Ngoài ra, các lập trình viên có thể dựa vào tốc độ xử lý để đánh giá hiệu quả của một phần mềm. Do đó, bạn cần thuật toán để rút ngắn thời gian và cải thiện tốc độ chương trình đáng kể.
Không dừng lại ở đó, thuật toán còn giúp các lập trình viên sử dụng hợp lý các nguồn lực. Trong thời gian thực thi chương trình, máy tính sẽ cần một dung lượng bộ nhớ trống, chắc chắn sẽ có các chương trình chiếm nhiều dung lượng của bộ nhớ. Do đó, việc chọn đúng thuật toán sẽ giúp bạn đảm bảo chương trình sử dụng ít bộ nhớ nhất có thể.
Các thuật toán cơ bản lập trình viên cần biết
1. Thuật toán sắp xếp (Sorting algorithm) là gì?
Thuật toán sắp xếp được thiết kế để sắp xếp một dãy các phần tử theo thứ tự nhất định, nhằm tìm kiếm và truy cập dễ dàng hơn. Có nhiều thuật toán sắp xếp khác nhau, mỗi thuật toán có cách tiếp cận riêng để thực hiện quá trình sắp xếp. Dưới đây là các thuật toán sắp xếp phổ biến:
- Thuật toán sắp xếp chèn (Insertion Sort)
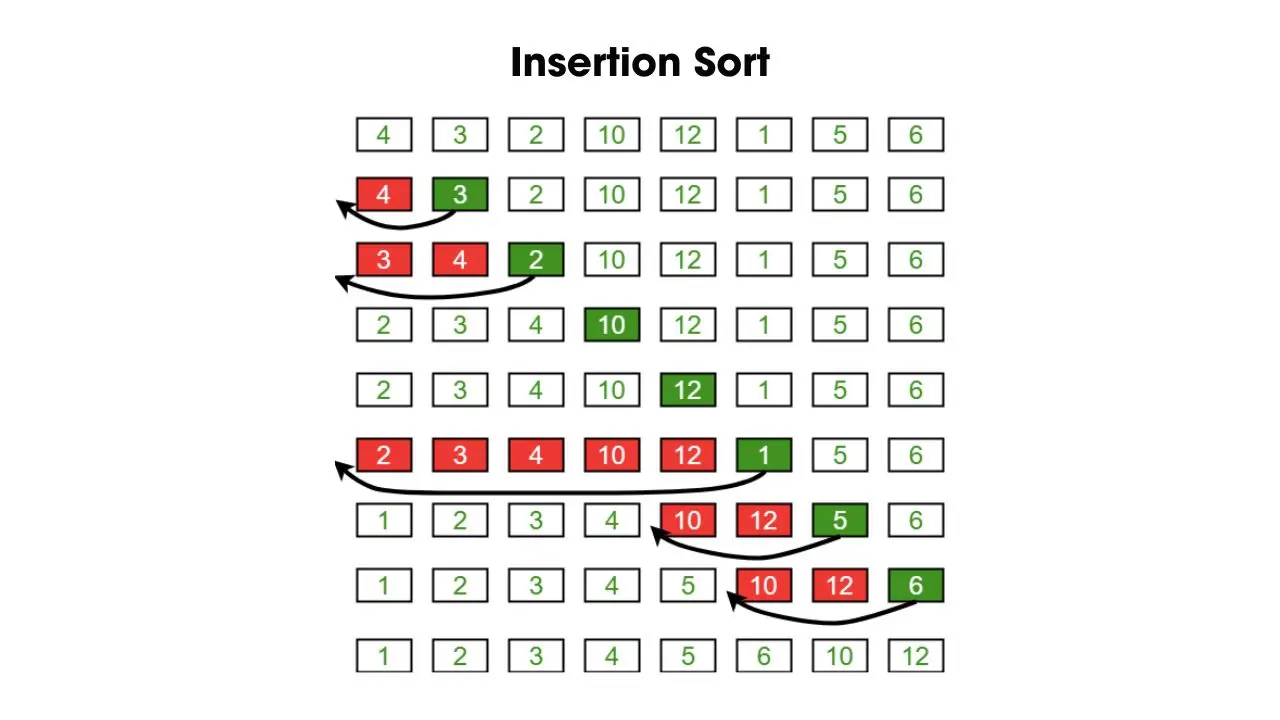
Cách thức hoạt động của thuật toán sắp xếp chèn là duyệt từng phần tử và chèn từng phần tử đó vào vị trí đúng trong mảng con, tức là dãy số từ đầu đến phần tử đó. Bắt đầu từ giá trị thứ 2 cho đến giá trị cuối cùng và so sánh các giá trị với vị trí trước đó. Mỗi lần chèn một phần tử mới, mảng con vẫn đảm bảo tính chất tăng dần của dãy số. Đây là thuật toán nhanh và hiệu quả thường sử dụng phổ biến trên các tập dữ liệu nhỏ.
- Thuật toán sắp xếp chọn (Selection Sort)
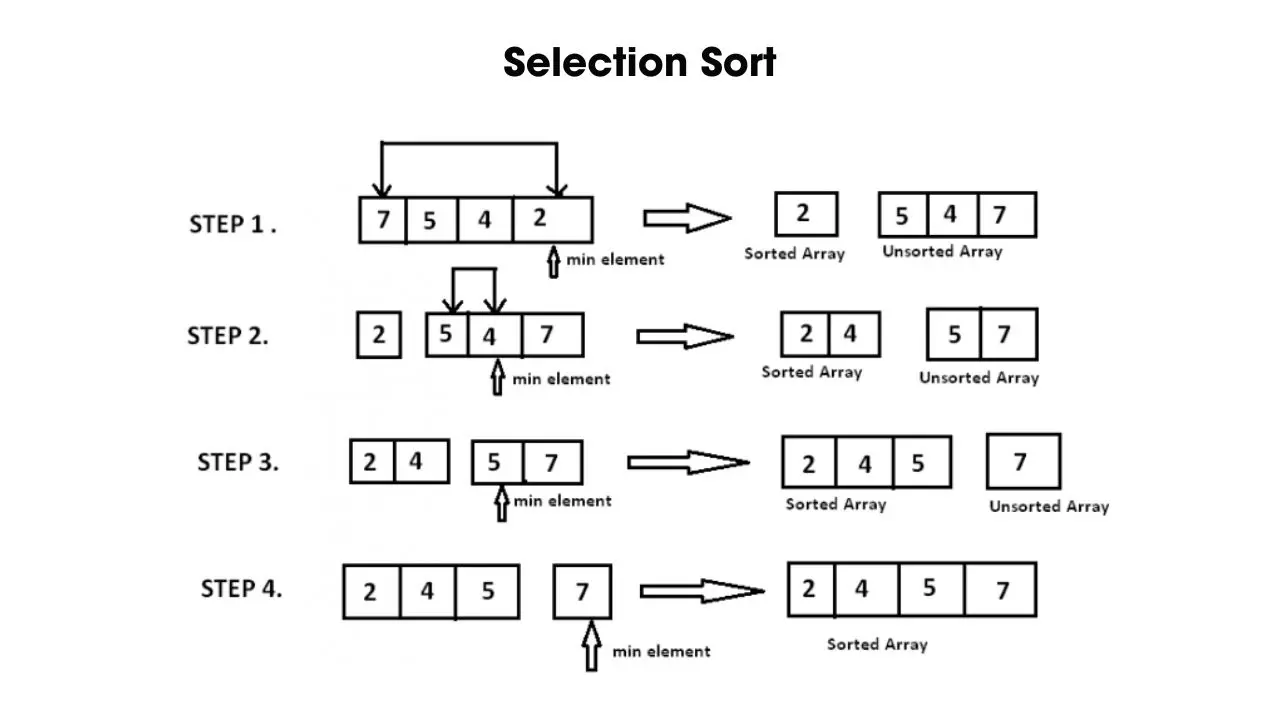
Thuật toán sắp xếp chọn hoạt động bằng cách đi tìm phần tử có giá trị nhỏ nhất trong mảng và đặt nó ở đầu dãy, sau đó tiếp tục quá trình tìm kiếm và đặt các phần tử nhỏ nhất tiếp theo vào vị trí kế tiếp. Phần đã được sắp xếp nằm ở đầu bên trái và phần chưa được sắp xếp sẽ ở đầu bên phải. Thuật toán này thường phù hợp với các tập dữ liệu nhỏ.
- Thuật toán sắp xếp nổi bọt (Bubble Sort)
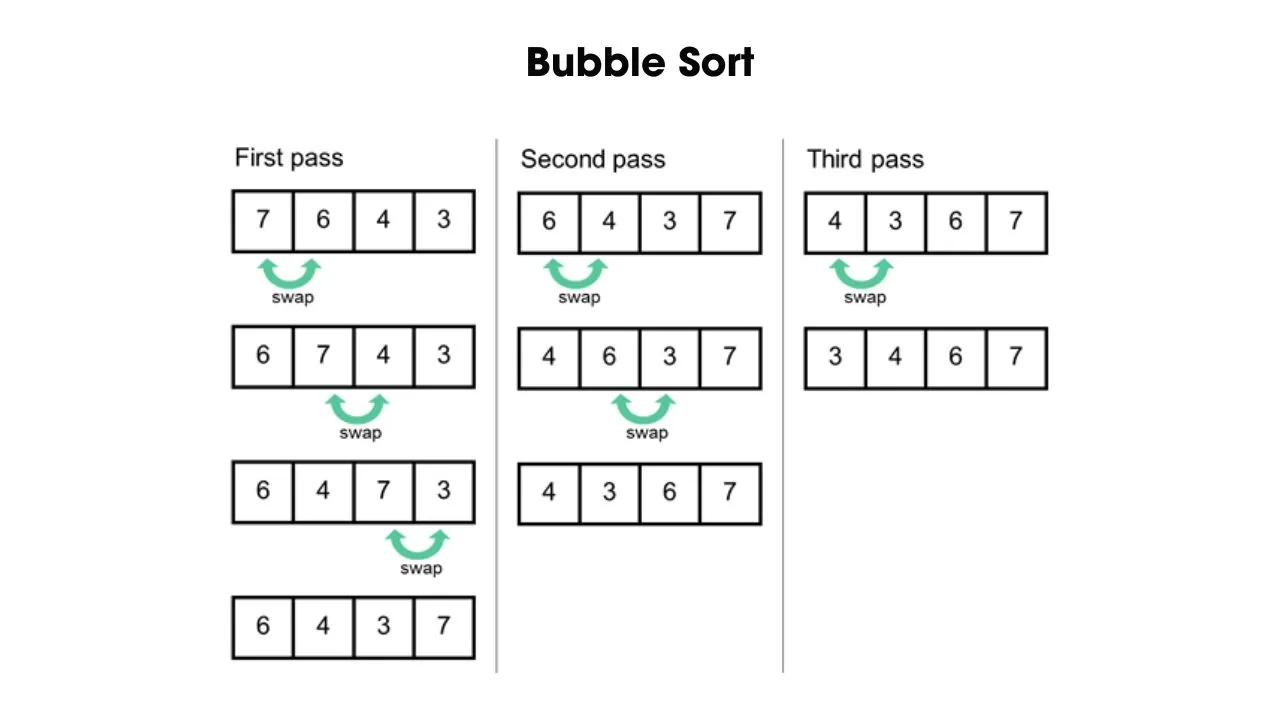
Bubble Sort là thuật toán có cách thức hoạt động tương đối đơn giản, bằng cách duyệt qua các phần tử trong danh sách và thực hiện hoán đổi vị trí các phần tử liền kề nếu chúng đứng sai thứ tự. Thuật toán này có thể thực hiện từ trên xuống (bắt đầu từ bên trái) hoặc từ dưới lên (bắt đầu từ bên phải) cho đến khi không còn phần tử nào trong danh sách bị thay thế.
- Thuật toán sắp xếp nhanh (Quick Sort)
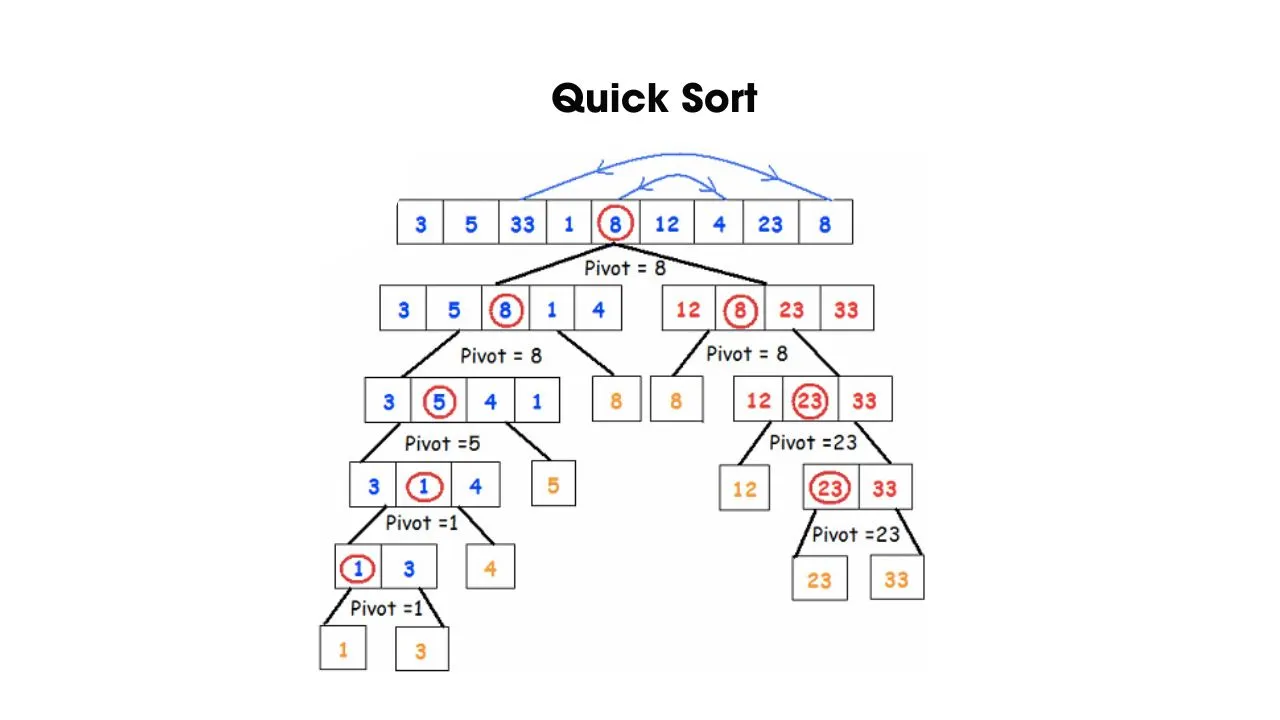
Quick sort là thuật toán áp dụng cách thức Divide and Conquer – “chia để trị”. Thuật toán này sẽ chọn một phần tử trong dãy số làm phần tử chốt (pivot). Sau đó, chúng sẽ phân chia dãy số thành 2 dãy con, dãy con trái (Left) là những phần tử nhỏ hơn pivot và dãy con phải (Right) là những phần tử lớn hơn pivot. Quá trình này được lặp lại cho đến khi độ dài của các mảng con đều có giá trị bằng 1 và tạo ra tập dữ liệu được sắp xếp đầy đủ.
- Thuật toán sắp xếp trộn (Merge Sort)
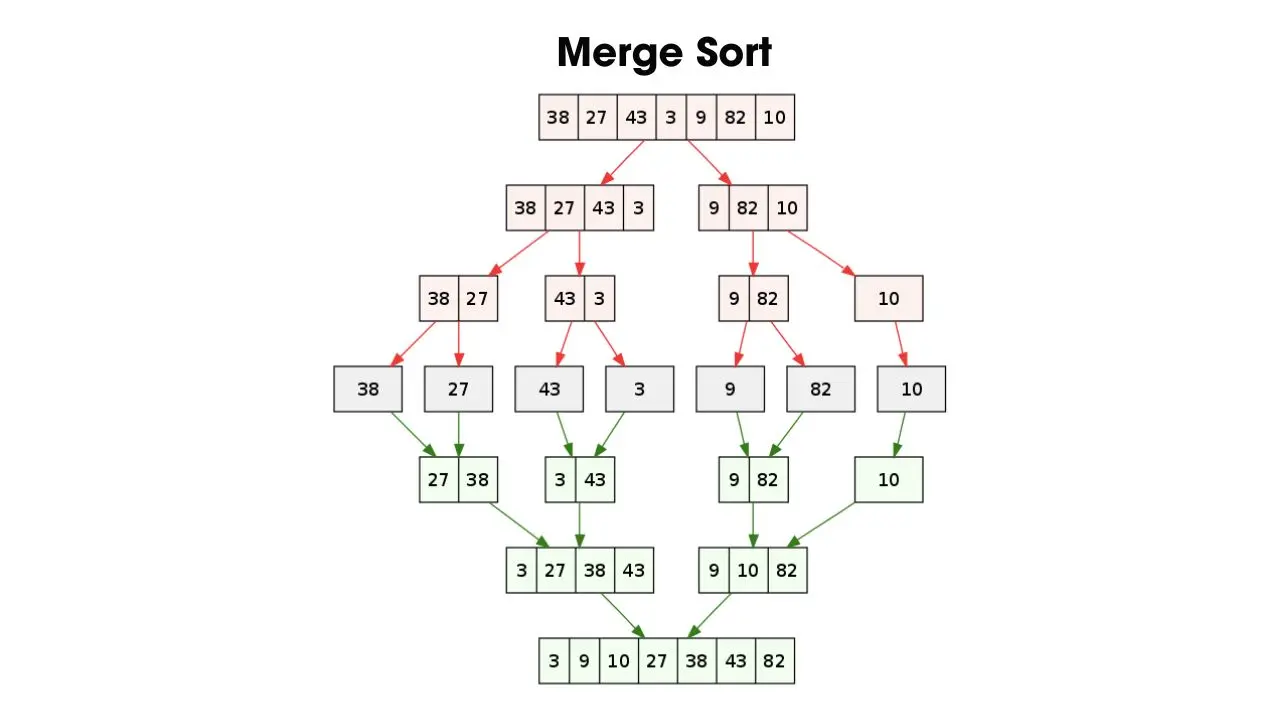
Merge Sort có phương pháp “chia để trị” giống với thuật toán Quick Sort, thường được sử dụng để giải quyết các tập dữ liệu lớn và phức tạp. Thuật toán sắp xếp trộn sẽ chia cấu trúc dữ liệu thành 2 nửa và tiếp tục lặp lại ở nửa mảng đã chia cho đến khi mỗi phần chỉ còn một hoặc hai mục.
Sau đó, sắp xếp từng phần nhỏ của dãy số bằng cách lặp lại quy trình chia đối với mỗi phần. Khi mỗi phần đã được sắp xếp, trộn chúng lại với nhau để tạo ra một dãy số hoàn chỉnh.
2. Thuật toán tìm kiếm (Searching Algorithms) là gì?
Tìm kiếm là chức năng cơ bản nhất nhưng đóng vai trò quan trọng nhất trong lập trình. Có 4 thuật toán tìm kiếm được sử dụng phổ biến hiện nay:
- Thuật toán tìm kiếm tuyến tính (Linear Search)
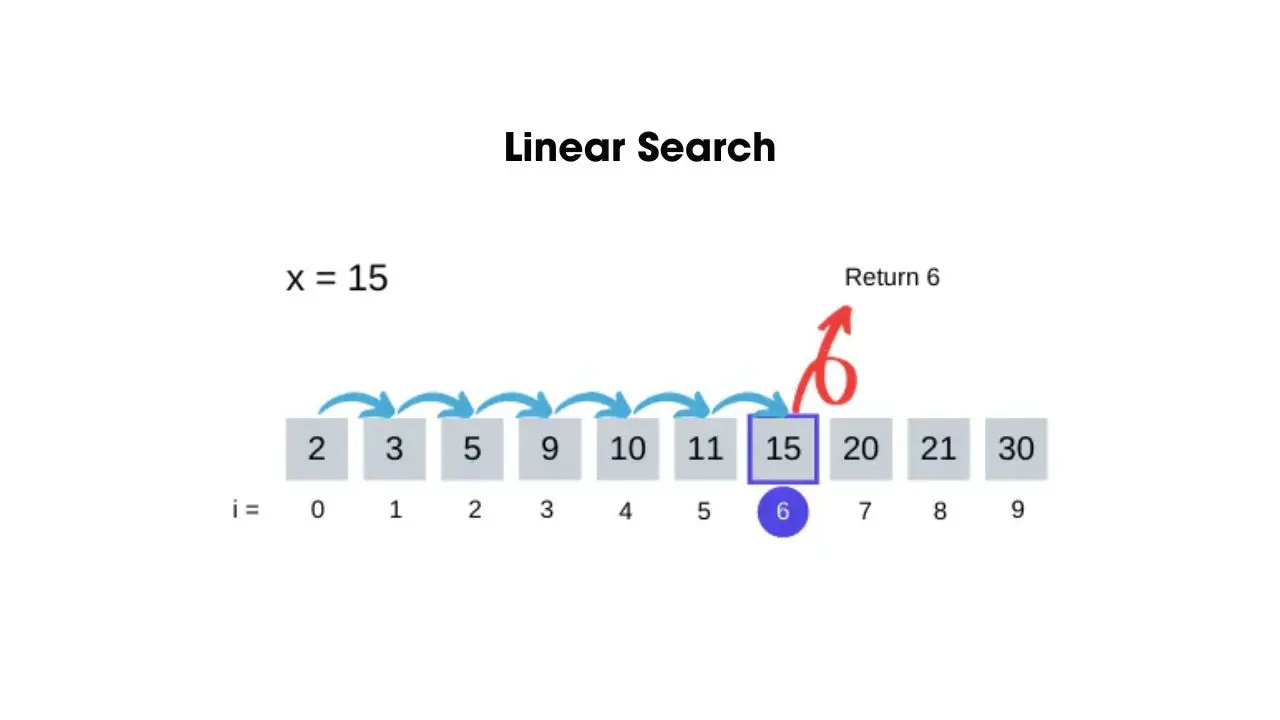
Thuật toán tìm kiếm tuyến tính còn được gọi là thuật toán tìm kiếm tuần tự (Sequential Search). Cách thức hoạt động của thuật toán này là duyệt lần lượt qua tất cả các phần tử trong danh sách cho đến khi thấy được phần tử cần tìm hoặc đã duyệt hết danh sách.
- Thuật toán tìm kiếm nhị phân (Binary Search)
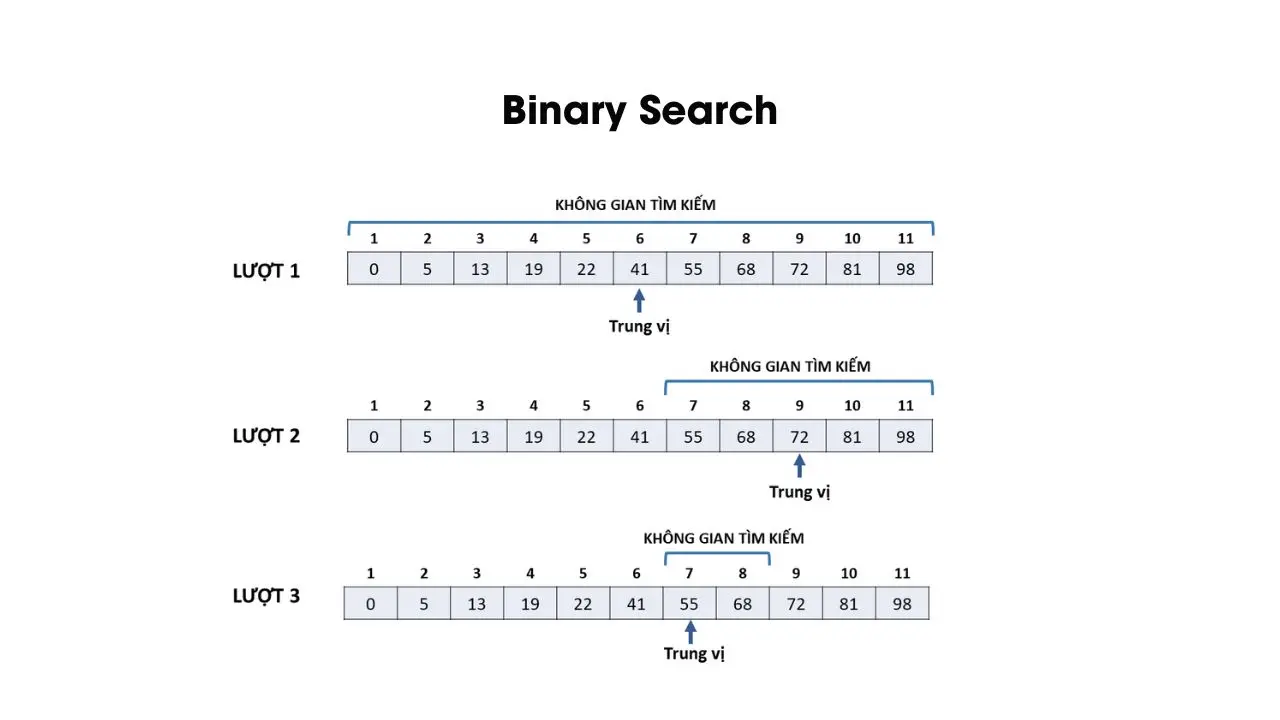
Thuật toán tìm kiếm nhị phân còn được gọi là thuật toán tìm kiếm nửa khoảng (half-interval search) hay thuật toán tìm kiếm logarit (logarithmic search). Cách thức hoạt động của thuật toán này dựa trên việc chia đôi khoảng cần xét và tìm kiếm trong nửa khoảng có thể chứa giá trị cần tìm. Lặp lại quá trình cho đến khi không thể chia đôi khoảng được nữa. Thuật toán tìm kiếm nhị phân thường được áp dụng cho các danh sách đã có thứ tự hoặc đã được sắp xếp.
- Thuật toán tìm kiếm nhảy (Jump Search)
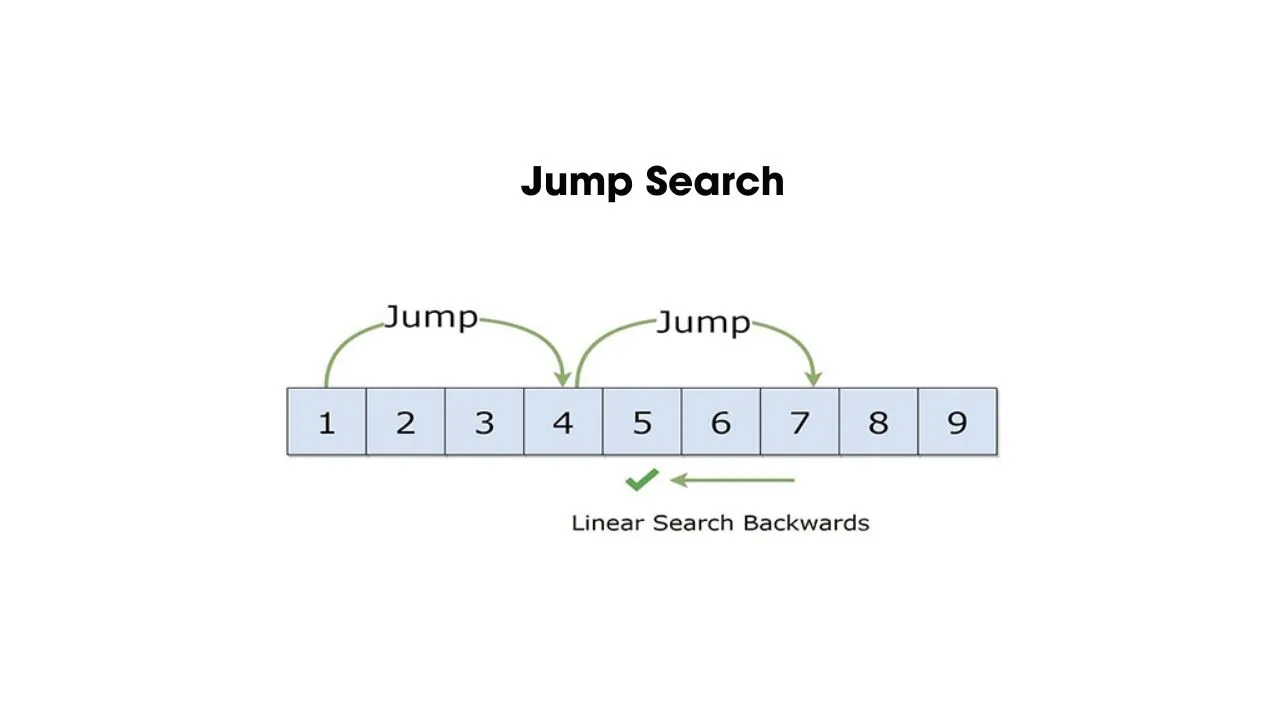
Thuật toán tìm kiếm nhảy thường phù hợp với dãy số đã được sắp xếp. Nó hoạt động bằng cách nhảy qua các phần tử với một khoảng cố định, thường là căn bậc hai của độ dài dãy số. Bắt đầu từ phần tử đầu tiên, Jump Search nhảy qua các phần tử với khoảng đã xác định cho đến khi vượt qua giá trị cần tìm. Sau đó thực hiện tìm kiếm tuyến tính trong khoảng đó.
- Thuật toán tìm kiếm nội suy (Interpolation Search)
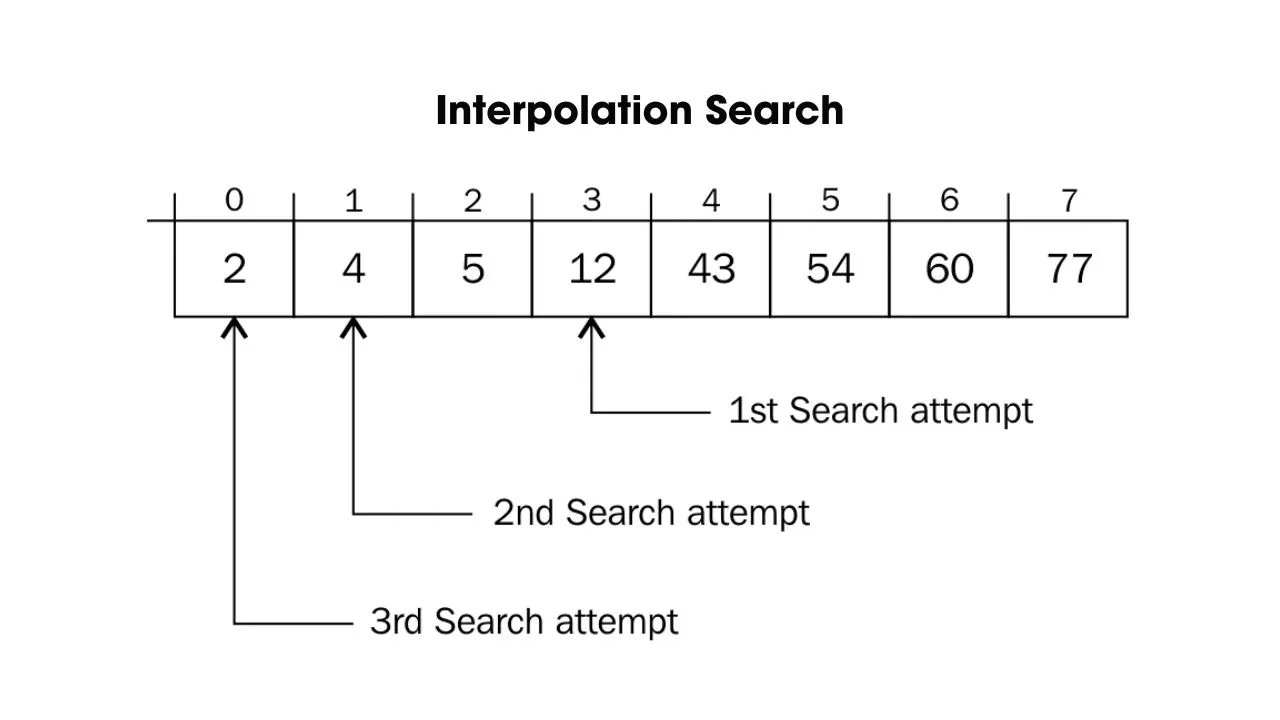
Thuật toán tìm kiếm nội suy được cải tiến từ thuật toán tìm kiếm nhị phân. Thuật toán này xác định điểm gần với vị trí phần tử cần tìm để tối ưu thời gian tìm kiếm và giảm độ phức tạp của thuật toán.
Tuy nhiên, trong trường hợp xấu như dãy tăng hoặc giảm phân bố không đều, độ phức tạp của thuật toán là O(n), thuật toán tìm kiếm nội suy không khác so với khi dùng thuật toán tìm kiếm tuyến tính. Vì thế, bạn nên sử dụng thuật toán tìm kiếm nhị phân để đảm bảo độ phức tạp của thuật toán là O(log(n)).
3. Thuật toán đồ thị (Graph Algorithms)
Đồ thị là công cụ quan trọng trong trực quan hóa dữ liệu (Data Visualization), được dùng để biểu diễn các mục dữ liệu thành các nút (nodes) được kết nối với nhau trong cùng một mạng.
- Thuật toán tìm kiếm theo chiều rộng (Breadth-First Search)
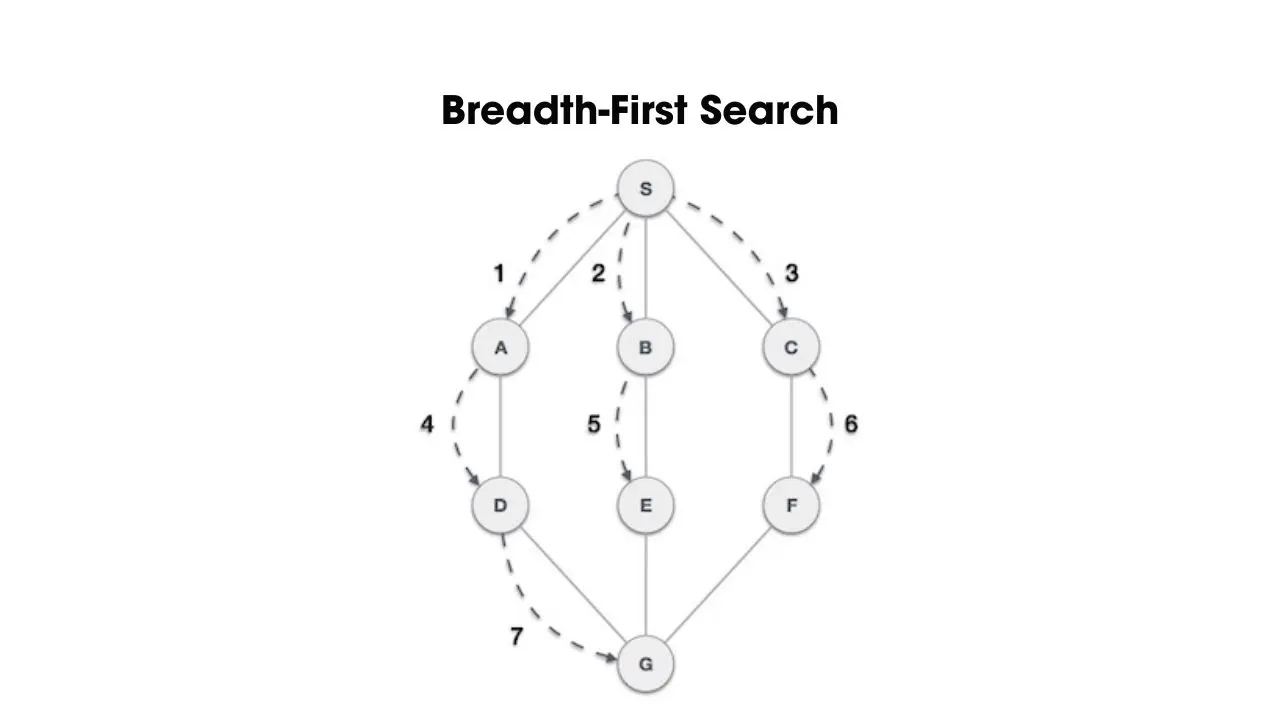
Breadth-First Search (viết tắt là BFS) là sử dụng cấu trúc dữ liệu hàng đợi (queue) để ghi nhớ các đỉnh liền kề và tìm kiếm theo thứ tự ưu tiên chiều rộng. Cụ thể là từ một đỉnh gốc, thuật toán này sẽ duyệt qua các đỉnh con liền kề (nodes con trên cây) của đỉnh đó. Sau đó, lưu các đỉnh con liền kề vào stack, từ các đỉnh con này tiếp tục tìm kiếm các đỉnh con của các đỉnh con đó. Tiếp tục thực hiện lặp như vậy cho đến khi không còn một nút con nào trong cây hoặc đồ thị. Đây là phương pháp giúp tìm đường ngắn nhất qua các nodes của cấu trúc đồ thị.
- Thuật toán tìm kiếm theo chiều sâu (Depth-First Search)
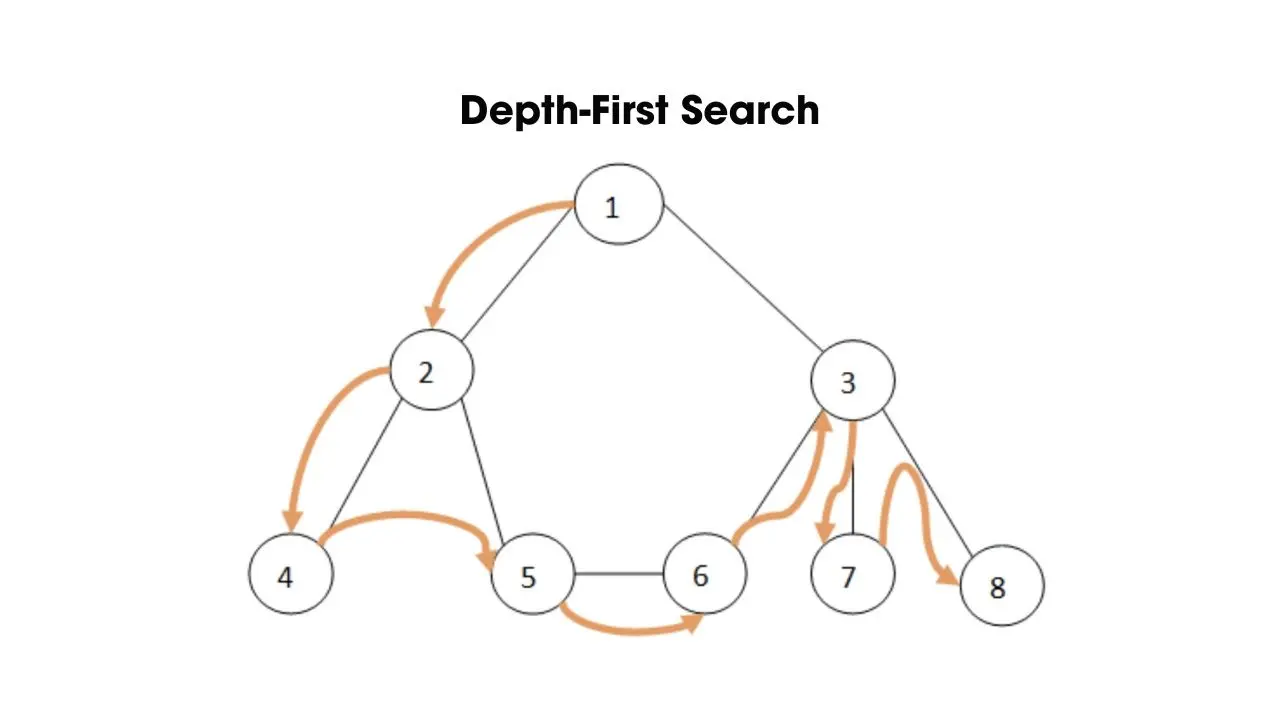
Depth-First Search (viết tắt là DFS) là thuật toán được sử dụng để tìm kiếm hoặc duyệt trên cấu trúc dữ liệu dạng cây. DFS sẽ chọn 1 node gốc, rồi triển khai khám phá node này. Sau đó, duyệt qua hết các đỉnh con của đỉnh hiện tại rồi tiếp tục thực hiện thuật toán này cho từng đỉnh con. Tiến hành lặp đi lặp lại thuật toán này với tất cả các đỉnh con cho tới khi không còn đỉnh con nào khám phá. Lúc này, thuật toán quay lại đỉnh gốc và khám phá các đỉnh con còn lại.
- Thuật toán Dijkstra (Shortest-Path)
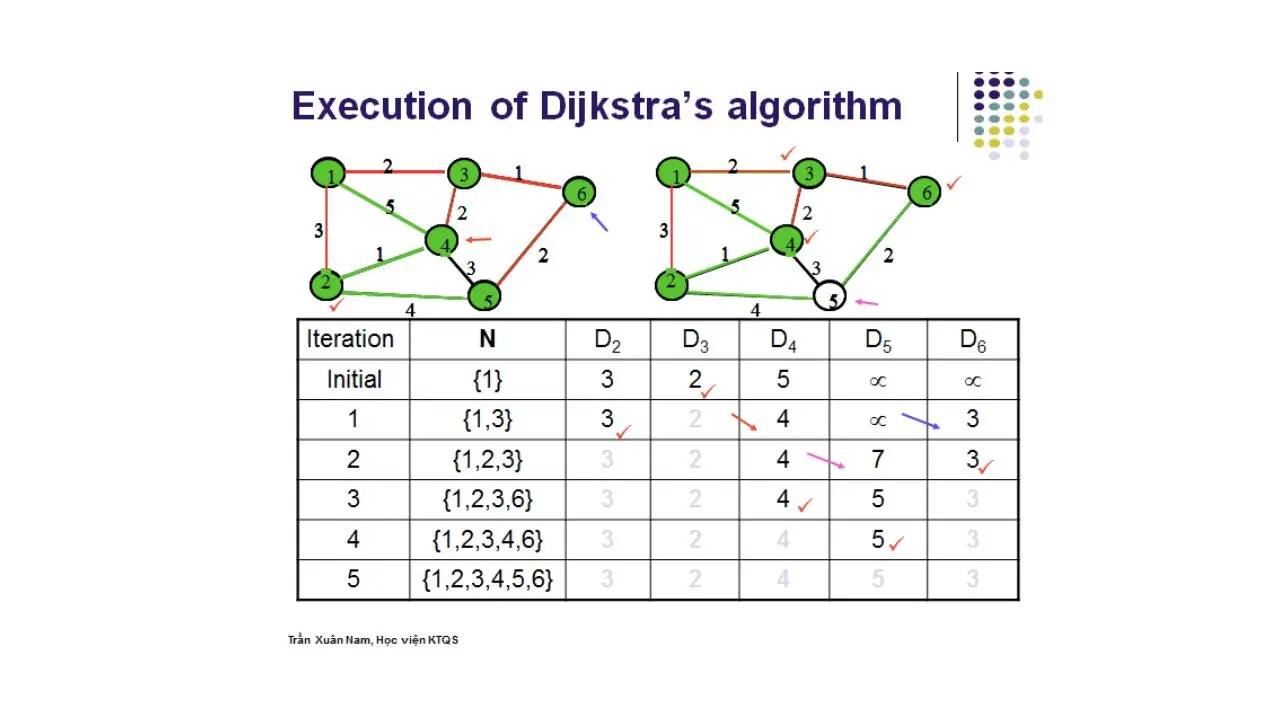
Thuật toán Dijkstra được dùng để giải quyết các bài toán tìm đường đi ngắn nhất từ một điểm được cho trước đến các điểm còn lại trong đồ thị hướng không có cạnh mang trọng số âm. Thuật toán Dijkstra thường được dùng trong định tuyến với 1 chương trình con trong các thuật toán đồ thị hoặc trong công nghệ GPS – hệ thống định vị toàn cầu. Ứng dụng nổi tiếng của thuật toán này là được sử dụng trong bản đồ Google để tính toán các tuyến đường nhanh nhất giữa 2 điểm bất kỳ trên bản đồ và được cập nhật liên tục.
- Thuật toán Kruskal và Prim
Thuật toán Kruskal và Prim là 2 thuật toán được sử dụng để tìm cây bao trùm nhỏ nhất (MST) nhưng không phụ thuộc vào điểm bắt đầu của cấu trúc đồ thị vô hướng có trọng số. MST là trọng số tối thiểu của các cạnh được dùng để kết nối các nút hoặc các đỉnh trong một cấu trúc đồ thị.
- Thuật toán Kruskal sẽ thêm các cạnh có trọng số thấp nhất trong 1 cấu trúc cho đến khi chúng kết nối với nhau để tạo thành MST.
- Thuật toán Prim tìm MST bằng cách bắt đầu với 1 đỉnh ngẫu nhiên và xây dựng đến đỉnh tiếp theo thông qua các cạnh có trọng số thấp nhất.
4. Thuật toán Hashing
Hashing là thuật toán được dùng để phát hiện và xác định dữ liệu thông qua key, ID. Thuật toán này được sử dụng để quản lý cache, tìm ra lỗi, mã hóa và tra cứu. Thông thường, hashing được tích hợp sẵn vào key nhằm mục đích cho ra giá trị chính xác nhất. Đây cũng là mã định danh duy nhất cho các tập dữ liệu và các phép tính để người dùng có thể tạo các giá trị dữ liệu duy nhất.
5. Thuật toán lập trình động (Dynamic Programming Algorithms)
Lập trình động là một hàm giải quyết các vấn đề phức tạp về trí tuệ bằng cách tách vấn đề thành các bài toán con để giải quyết lần lượt. Tiếp đó, xây dựng lại thành vấn đề phức tạp với bộ nhớ của các kết quả nhỏ nhằm đưa ra câu trả lời cho vấn đề phức tạp gốc. Thuật toán lập trình động có thể tích hợp để ghi nhớ và cho phép lưu trữ ký ức về những vấn đề đã giải quyết trước đó. Trong các lần tiếp theo nếu vấn đề đó lại xuất hiện thì thuật toán này sẽ giải quyết nhanh hơn nhiều.
6. Thuật toán phân tích liên kết (Link Analysis)
Thuật toán phân tích liên kết thường được áp dụng trong lĩnh vực mạng và cung cấp khả năng xác định sự tương quan giữa các thực thể khác nhau trong một miền, đặc biệt quan trọng đối với các công cụ tìm kiếm.
Thuật toán phân tích liên kết sử dụng 1 biểu diễn đồ họa và ma trận phức tạp để liên kết các căn cứ giống nhau trong các miền hiện tại. Thuật toán này thường ứng dụng phổ biến trong các công cụ tìm kiếm mở rộng như Google, Facebook, Twitter,…
7. Thuật toán Mô-đun
Thuật toán Mô-đun là quá trình phân tích các thuật toán mã hóa phức tạp, giúp chúng trở nên đơn giản và dễ thực hiện hơn nhiều. Trong trường hợp số học mô-đun, các thông số hiện tại được xử lý chỉ là số nguyên, và các phép toán được sử dụng chủ yếu là cộng, trừ, nhân và chia.
8. Thuật toán biến đổi Fourier
Thuật toán biến đổi Fourier được biết đến là một trong những thuật toán đơn giản nhưng vô cùng mạnh mẽ. Thuật toán này được dùng nhằm chuyển đổi tín hiệu từ tên miền thời gian sang tên miền tần số và ngược lại.
Hiện nay, thuật toán này được ứng dụng phổ biến trong các mạng kỹ thuật số như internet, wifi, điện thoại, máy tính, vệ tinh, bộ định vị,…
9. Thuật toán mã hóa Huffman là gì?
Thuật toán mã hóa Huffman là một thuật toán nén dữ liệu được sử dụng để giảm dung lượng của thông tin vô cùng hiệu quả. Thuật toán này hoạt động bằng cách xác định tần số xuất hiện của các ký tự trong tập tin hoặc chuỗi cần nén. Sau đó xây dựng cây Huffman dựa trên tần số xuất hiện, với các nút biểu diễn các ký tự và tần số của chúng, chuyển đổi dữ liệu, giảm dung lượng thông tin.
Kết luận
Hy vọng những thông tin hữu ích mà Vieclam24h.vn chia sẻ trong bài viết trên đã giúp các bạn đã hiểu rõ thuật toán là gì và vai trò của các thuật toán trong lập trình. Việc nắm vững các thuật toán cơ bản là chìa khóa để bạn có thể phát triển sự nghiệp lập trình viên bền vững trong thời đại công nghệ phát triển hiện nay.





_172431175235.png?v=220513)
Bên cạnh đó, Nghề Nghiệp Việc Làm 24h cung cấp công cụ tạo CV online với hàng trăm mẫu CV hoàn toàn miễn phí. Ngoài nội dung đúng chuẩn dựa theo vị trí công việc và lĩnh vực ứng tuyển, các bạn có thể thỏa sức sáng tạo CV cá nhân với chức năng tùy chỉnh màu sắc, nội dung, bố cục,… để tìm việc nhanh chóng tại môi trường làm việc mơ ước.
Xem thêm: Lương lập trình viên hiện nay bao nhiêu? Làm sao cải thiện mức lương?
